
Pourquoi Golem.ai a décidé d’expérimenter les LLMs ?
Chez Golem.ai, nous croyons à la complémentarité des approches Symbolique et Générative de l’IA.
Le premier épisode de cette série d’articles l’explique.
Nous vous invitons à y jeter un coup d’oeil si vous ne l’avez pas encore fait.
Pourquoi choisir LlaMA-2 ?
Meta, la société mère de Facebook, a fait sensation dans le secteur de l’intelligence artificielle (IA) en juillet dernier avec le lancement de LLaMA 2, un modèle de langage à grande échelle (LLM) open-source conçu pour défier les pratiques restrictives de ses principaux concurrents technologiques.
Contrairement aux systèmes d’IA lancés par Google, OpenAI et d’autres (comme Apple avec Apple GPT ?), qui sont étroitement protégés par des modèles propriétaires, Meta publie gratuitement le code et les données de LlaMA 2 pour permettre aux chercheurs du monde entier de construire et d’améliorer la technologie !
Voici les cinq principales caractéristiques de LlaMA 2 :
- LlaMA 2 surpasse les autres LLM open-source dans les tests de raisonnement, de compétence en codage et de connaissances.
- Le modèle a été entraîné sur près de deux fois plus de données que la version 1, soit un total de 2 billions de jetons. En outre, l’entraînement a inclus plus d’un million de nouvelles annotations humaines et un réglage fin pour les compléments de conversation.
- Le modèle existe en trois tailles, chacune entraînée avec 7, 13 et 70 milliards de paramètres.
- LlaMA 2 prend en charge des contextes plus longs, jusqu’à 4096 tokens.
- La version 2 a une licence plus permissive que la version 1, autorisant une utilisation commerciale.
Premiers tests en mode “Test and learn” avec Replicate.com
Pour tester LlaMA-2, nous avons d’abord opté pour le SaaS Replicate.com
Cela vous permet de payer au fur et à mesure, sans avoir besoin d’installer de logiciel sur du matériel existant.
Une première approche parfaite pour expérimenter !
Cependant, pour des raisons de confidentialité et d’intelligence économique, nous avons opté pour une deuxième approche, expliquée ci-dessous.
Pourquoi LlaMA-2 sur des GPUs internes après le SaaS Replicate.com ?
Chez Golem.ai, l’intelligence artificielle de confiance, la souveraineté des données, la sécurité et le contrôle de l’ensemble de la chaîne de valeur sont les choses les plus importantes.
Pour cette raison, nous avons décidé de réaliser notre propre benchmark en utilisant les ressources matérielles de notre fournisseur de cloud français Scaleway.
Bien que le modèle LlaMA-2 soit gratuit à télécharger et à utiliser, il convient de noter que l’auto-hébergement de ce modèle nécessite une puissance GPU importante pour un traitement optimal.
LlaMA 2 est disponible en trois tailles : 7 milliards, 13 milliards et 70 milliards de paramètres, selon le modèle choisi.
Pour les besoins de cette démonstration, nous utiliserons le modèle 70b pour obtenir la meilleure pertinence !
Mise en place de la solution GPU interne
Entrons dans le vif du sujet 😈
Vue d’ensemble de l’intégration
- L’utilisateur fournit une entrée : une invite de commande (c’est-à-dire qu’il pose une question).
- Un appel API est effectué vers le serveur Llama.cpp, où l’invite de commande est soumise et la réponse générée par Llama-2 est obtenue et affichée à l’utilisateur.
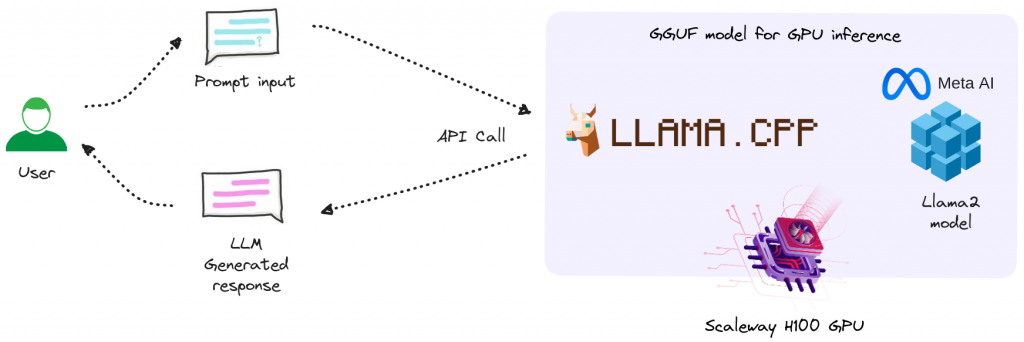
Nous exécutons le modèle LlaMA-2 70B à l’aide de Llama.cpp, avec le pilote NVIDIA CUDA 12.2 sur une Ubuntu 22.04.
Llama.cpp est une bibliothèque C/C++ pour l’inférence des modèles LlaMA/LlaMA-2.
Pour ce scénario, nous utiliserons le H100-1-80G, le matériel le plus puissant de leur gamme de GPU étant H100-2-80G, de notre fournisseur français Cloud Scaleway.
La gamme de GPU de Scaleway comprend quatre produits dédiés à des utilisations différentes 🚀
| Machine | GPU | Mémoire GPU (VRAM) | Processeur | Coeurs physiques (vCPU) | RAM |
|---|---|---|---|---|---|
| Render-S | Dedicated NVIDIA Tesla P100 16GB PCIe | 16GB CoWoS HBM2 | Intel Xeon Gold 6148 cores | 10 | 42 GB |
| H100-1-80G | H100 PCIe Tensor Core GPU | 80GB(HBM2e) | AMD EPYC™ 9334 | 24 | 240 GB |
| H100-2-80G | 2x H100 PCIe Tensor Core GPU | 2x 80GB(HBM2e) | AMD EPYC™ 9334 | 48 | 480 GB |
La méthode de mise en œuvre de la solution est précisée dans les lignes suivantes.
Nous estimons qu’il faut environ 30mn pour la mettre en place, sous réserve que vous répondiez à nos exigences OS, logicielles, matérielles et que vous ne rencontriez pas d’erreurs 🙂 .
A. Installation
Deux voies possibles :
1. La méthode officielle d’exécuter LlaMA-2 est de passer par leur dépôts.
- Avantages :
- Méthode officielle
- Inconvénients :
- Développé en Python (lenteur d’exécution et consommation excessive de RAM)
- Dysfonctionnement de l’accélération GPU H100
2. Exécuter LlaMA-2 via l’interface Llama.cpp
- Avantages :
- Cette implémentation en C/C++ pur est plus rapide et plus efficace que son homologue officiel Python, et prend en charge l’accélération GPU H100 via CUDA et Metal d’Apple. Cela accélère considérablement l’inférence sur le CPU et rend l’inférence sur le GPU H100 plus efficace.
- Inconvénients :
- Méthode communautaire (non officielle)
Nous avons choisi d’utiliser Llama.cpp pour cette implémentation.
B. Modèles disponibles
Vérifier le type de modèle :
https://www.hardware-corner.net/llm-database/Llama-2/
/!\ Llama.cpp ne supporte plus les modèles GGML
https://huggingface.co/TheBloke/Llama-2-70B-Chat-GGML
⇒ Remplacé par des modèles GGUF
https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF (basée sur Llama-2-70b-chat-hf)
C. Processus d’installation
- Installez le pilote NVIDIA CUDA (s’il n’est pas installé sur votre machine GPU H100).
Pour commencer, installons le pilote NVIDIA CUDA sur Ubuntu 22.04. Le guide présenté ici est le même que celui de la page de téléchargement de CUDA Toolkit fournie par NVIDIA.
$ wget <https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb>
$ sudo dpkg -i cuda-keyring_1.1-1_all.deb
$ sudo apt-get update
$ sudo apt-get -y install cuda-toolkit-12-3
Après l’installation, le système doit être redémarré. Cela permet de s’assurer que les modules du noyau des pilotes NVIDIA sont correctement chargés avec dkms. Ensuite, vous devriez être en mesure de voir vos GPU H100 en utilisant nvidia-smi.
$ sudo shutdown -r now
llm@h100-ftw:~$ nvidia-smi
Wed Oct 4 08:44:54 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.104.12 Driver Version: 535.104.12 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA H100 PCIe On | 00000000:01:00.0 Off | 0 |
| N/A 42C P0 51W / 350W | 4MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+2. Assurez-vous d’avoir le binaire nvcc dans votre chemin d’accès (path)
llm@h100-ftw:~$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Tue_Aug_15_22:02:13_PDT_2023
Cuda compilation tools, release 12.2, V12.2.140
Build cuda_12.2.r12.2/compiler.33191640_0
*si la commande est introuvable : ln -s /usr/local/cuda/bin/ /bin/3. Clonez et compilez Llama.cpp
Après l’installation de NVIDIA CUDA, toutes les conditions préalables à la compilation de Llama.cpp sont déjà remplies. Il suffit de cloner llama.cpp et de le compiler.
$ git clone <https://github.com/ggerganov/llama.cpp>
$ cd llama.cpp
Pour faire correspondre CUDA arch et CUDA gencode pour les différentes architectures NVIDIA :
Modifier le Makefile avant la compilation avec NVCCFLAGS += -arch=all-major au lieu de NVCCFLAGS += -arch=native
$ make
$ make clean && LLAMA_CUBLAS=1 make -j
4. Téléchargez et exécutez LLaMA-2 70B
Nous utilisons le modèle converti et quantifié de l’excellent utilisateur de la communauté HuggingFace, TheBloke. Les modèles pré-quantifiés sont disponibles via ce lien . Dans le nom du dépôt de modèles, GGUF fait référence à un nouveau format de fichier de modèle introduit en août 2023 pour Llama.cpp.
Pour télécharger les fichiers du modèle, nous commençons par installer et initialiser git-lfs.
$ sudo apt install git-lfs
$ git lfs install
Vous devriez voir « Git LFS initialized » s’afficher dans le terminal après la dernière commande. Ensuite, nous pouvons cloner le dépôt, mais avec des liens vers les fichiers au lieu de les télécharger tous.
cd models
GIT_LFS_SKIP_SMUDGE=1 git clone <https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF>
$ cd Llama-2-70B-GGUF
$ git lfs pull --include llama-2-70b-chat.Q6_K.gguf-split-a
$ git lfs pull --include llama-2-70b-chat.Q6_K.gguf-split-b
$ cat llama-2-70b-chat.Q6_K.gguf-split-* > llama-2-70b-chat.Q6_K.gguf && rm llama-2-70b-chat.Q6_K.gguf-split-*
Le seul fichier dont nous avons besoin est llama-2-70b-chat.Q6_K.gguf, qui est le modèle LlaMA 2 70B traité à l’aide d’une des méthodes de quantification à 6 bits.
Ce modèle nécessite en moyenne 60 Go de mémoire. Sur le H100, nous avons 80GB (HBM2e) de VRAM. Le traitement sera effectué entièrement sur le GPU du H100 !

$ ./main -ngl 100 -t 1 -m llama-2-70b-chat.Q6_K.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "[INST] <<SYS>>\\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\\n<</SYS>>\\n{prompt}[/INST]"
5. Servir Llama-2 70B
De nombreux programmes utiles sont construits lorsque nous exécutons la commande make pour Llama.cpp.
main est celui à utiliser pour générer du texte dans le terminal.
perplexity peut être utilisé pour calculer la perplexité par rapport à un ensemble de données donné à des fins d’analyse comparative.
Dans cette partie, nous examinons le programme server, qui peut être exécuté pour fournir un serveur API HTTP simple pour les modèles compatibles avec Llama.cpp.
https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md
$ ./server -m models/Llama-2-70B-chat-GGUF/llama-2-70b-chat.Q6_K.gguf \\
-c 4096 -ngl 100 -t 1 --host 0.0.0.0 --port 8080
Remplacez -t 32 par le nombre de cœurs physiques du processeur. Par exemple, si le système a 32 cœurs / 64 threads, utilisez -t 32. Si vous déchargez complètement le modèle sur le GPU, utilisez -t 1 (comme sur le H100).
Remplacez -ngl 80 par le nombre de couches GPU pour lesquelles vous disposez de VRAM (comme H100). Utilisez -ngl 100 pour décharger toutes les couches sur la VRAM – si vous avez suffisament de VRAM. Sinon, vous pouvez décharger partiellement autant de couches que vous avez de VRAM, sur un ou plusieurs GPU.
Paramètres: https://huggingface.co/TheBloke/Llama-2-70B-Chat-GGML#how-to-run-in-llamacpp
llm_load_tensors: ggml ctx size = 0.23 MB
llm_load_tensors: using CUDA for GPU accelerationllm_load_tensors: mem required = 205.31 MB
llm_load_tensors: offloading 80 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 83/83 layers to GPU
llm_load_tensors: VRAM used: 53760.11 MB
...................................................................................................
llama_new_context_with_model: n_ctx = 4096
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: offloading v cache to GPU
llama_kv_cache_init: offloading k cache to GPU
llama_kv_cache_init: VRAM kv self = 1280.00 MB
llama_new_context_with_model: kv self size = 1280.00 MB
llama_new_context_with_model: compute buffer total size = 573.88 MB
llama_new_context_with_model: VRAM scratch buffer: 568.00 MB
llama_new_context_with_model: total VRAM used: 55608.11 MB (model: 53760.11 MB, context: 1848.00 MB)
Explication des métriques de Llama.cpp :
Lorsque vous exécutez votre entrée, différentes métriques vous sont communiquées afin de mesurer sa performance.
llama_print_timings: load time = 59250.72 ms
llama_print_timings: sample time = 611.28 ms / 180 runs ( 3.40 ms per token, 294.47 tokens per second)
llama_print_timings: prompt eval time = 1597.63 ms / 508 tokens ( 3.14 ms per token, 317.97 tokens per second)
llama_print_timings: eval time = 11703.38 ms / 179 runs ( 65.38 ms per token, 15.29 tokens per second)
llama_print_timings: total time = 13958.06 ms
- temps de chargement : chargement du fichier modèle
- temps d’échantillonnage : génération de jetons à partir de l’invite/du fichier en choisissant le jeton probable suivant.
- temps d’évaluation de l’invite : temps nécessaire pour traiter l’invite/le fichier par LLaMa avant de générer un nouveau texte.
- eval time : temps nécessaire pour générer la sortie (jusqu’à
[end of text]ou la limite fixée par l’utilisateur). - total : ensemble
Comparaison entre Replicate.com et les GPU Nvidia H100 hébergés par Scaleway
Après avoir effectué une centaine de tests au total entre Replicate.com et le H100 de Nvidia hébergé par Scaleway, nous concluons que la différence d’exécution est de 40 % en faveur de l’utilisation des GPU H100-1-80G fournis par Scaleway.
Le score d’hallucination sur une échelle de 0 à 3 que nous attribuons à Golem.ai, qui représente la pertinence de la réponse à chaque test, n’est pas suffisamment représentatif d’une différence notable entre Replicate.com et Scaleway.
Pour en savoir plus, nous vous invitons à lire l’article sur le protocole de test LLM de Golem.ai
Conclusion et ouverture
Les cas d’utilisation vont bien au-delà de cette première expérience. Chez Golem.ai, nous pensons qu’il y a beaucoup d’autres façons d’utiliser les LLM avec notre technologie, y compris l’outillage et le support pour nos utilisateurs.
Ce n’est que le début d’une longue et passionnante aventure.
Il existe plusieurs Frameworks pour servir les LLM. Chacun a ses propres caractéristiques.
Dans cet article, nous avons expérimenté Llama.cpp en exécutant le modèle LLaMa-2 70b.
Pour en savoir plus sur ce sujet, veuillez lire l’article suivant, qui traite spécifiquement de ce sujet.



