
Green Tech, Tech for Good, Tech’Care… Autant de manières d’évoquer les impacts qu’ont les nouvelles technologies sur notre bilan carbone, que de lister les potentielles solutions. Avec plus de 53% des émissions de gaz à effet de serre générées par le numérique, les datas center et les infrastructures réseaux consomment autant que nous utilisons de données. Bien que fonctionner avec des IA sans entraînement réduit drastiquement cet impact, découvrez 5 solutions liées au traitement et au stockage de la data qui changent nos paradigmes…
#1 Faire le choix d’un cloud écologique
L’approche “Green” de l’IT nécessite d’appliquer des pratiques respectueuses de l’environnement directement au niveau de l’infrastructure. Les choix d’utilisation des technologies sont décisifs dans l’impact environnemental que vous aurez.
Scaleway un fournisseur à bonne efficacité énergétique
Les clusters kubernetes sont, dans notre cas, managés par un cloud provider de confiance : Scaleway. C’est auprès de ce cloud provider que nous consommons les ressources IT, déléguant la charge de la gestion physique des serveurs (Power, cooling, Device management etc…). Scaleway nous propose ici un datacenter disposant d’un système de refroidissement dit “adiabatique” ne nécessitant pas de climatisation ce qui permet à ce datacenter d’afficher un PUE (Power Usage Effectiveness) assez remarquable de 1,15.
Exploitation des possibilités d’infrastructure à la demande
Nous consommons les ressources nécessaires à nos besoins sur un mode de facturation dit ”à l’usage” et avons la capacité de remettre à disposition des autres clients de Scaleway les ressources que nous n’utilisons pas. La démarche est simple : dimensionner juste, au plus près du besoin de l’infrastructure IT qui supporte Golem.ai pour maximiser l’efficacité financière et environnementale.
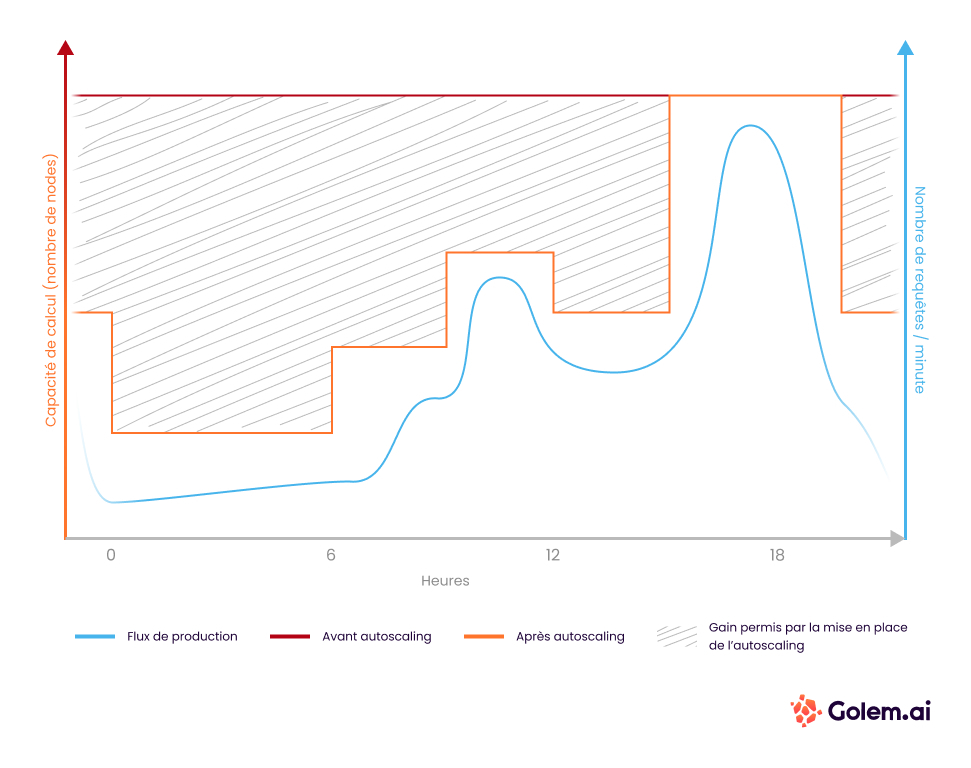
#2 Mettre en place un scaling automatique avec Keda
Initialement, notre plateforme était dimensionnée 24h/7 aux valeurs permettant d’assumer les pics de charges potentiels. Avec ce setup, notre performance restait bonne, mais nous avions un goût amer à la vue du gaspillage dont nous étions à l’origine, car les machines nous restaient allouées et sous tension mais inexploitées pendant nos heures creuses.
Pour y pallier, nous avons choisi d’exploiter les possibilités combinées de Horizontal Pod AutoScaling, Cluster Autoscaling et Keda afin d’assurer un provisionnement de ressources non pas de manière constante et élevée, mais au plus près de la demande.
Grâce à cette méthode nous sommes passés entre les mois de juin et août 2022 d’une consommation temps plein de 56 machines de production à 27 machines de production. Nous avons donc divisé par 2 l’utilisation de machines sur la seule plateforme de production par ce biais.
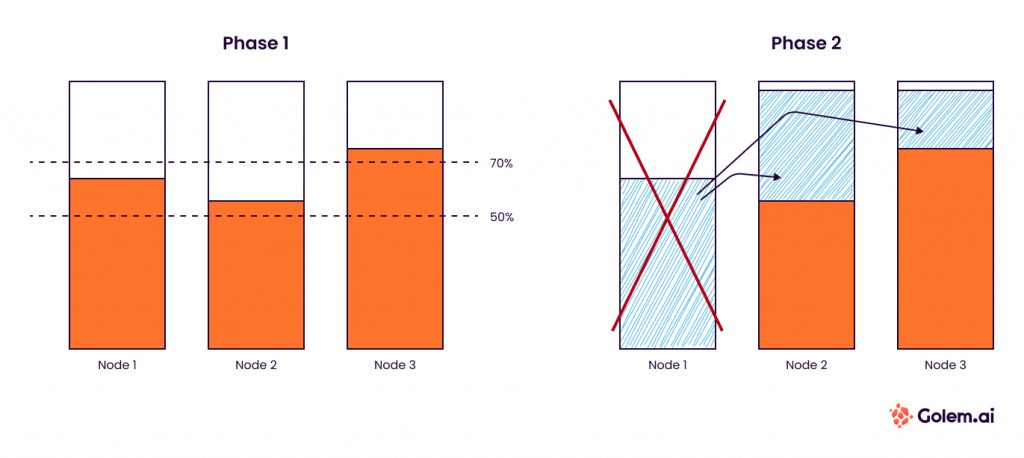
#3 Augmenter le niveau de remplissage des clusters kubernetes
Afin de supprimer des machine inutilisées de notre parc, le cluster autoscaller prend la décision de supprimer un nœud du cluster à partir d’un certain seuil de “Non utilisation”. Par défaut, c’est 50%. Ce choix est très sécuritaire car il permet dans le cas d’un cluster à 2 nœuds de quasi garantir que le second nœud peut assumer toute la charge seul.
Cette configuration a du sens pour les clusters avec peu de nœuds pour des raisons de résilience. Chez Golem.ai, nous sommes dans une configuration plus complexe comportant une évolution de nœuds comprise entre 14 pour les périodes creuses et 55 pour les périodes de charge intense. A cette échelle, la marge par nœud peut être réduite car la marge totale reste importante.
#4 Sensibiliser les usagers à l’utilisation responsable de la plateforme
Notre plateforme comporte aujourd’hui deux types d’utilisateurs :
- Les clients finaux qui utilisent le service pour sa promesse fonctionnelle
- Les configurateurs (collaborateurs de l’entreprise ou directement de Golem.ai) qui utilisent la plateforme pour ajuster les configurations d’IA qui consomme ce service de manière plus aléatoire et moins prédictible
C’est pourquoi nous avons intégré un système de tags permettant d’isoler ces deux usages. Le premier usage est appelé “Prod” et le nombre de réplica minimal est de 5 pods pour ces intelligences artificielles. Le second cas d’usage est appelé “Hors prod” avec un nombre de réplica allant de 1 jusqu’à 0 la nuit. C’est ce qu’on appelle le “scale down to 0”(0 pod).
Cette organisation impacte directement la performance. Les situations en “Prod” possèdent des ressources d’avance, ce qui permet au système de répondre directement, avec une bonne vélocité, et de s’adapter aux pics de charge en journée. Les situations en “Hors-prod” ne sont en revanche pas moins réactives, surtout si aucun pod n’est disponible au moment de la requête. Si l’intelligence artificielle n’a pas été sollicitée pendant un moment, elle possède un temps de provisionnement d’environ 1 minute… Un délai récurrent qui survient tous les matins que rencontrent les configurateurs. Finalement nous reproduisons chez Golem.ai le mode de fonctionnement des offres cloud dites serverless pour nos IA, nous héritons donc de sa principale contrainte couramment appelée le cold start.
Certains configurateurs n’utilisent pas correctement ce système de tags permettant de bénéficier du scale down to 0 . Certains ont remarqué que le tag “Prod” était plus réactif et en disposent plus régulièrement. C’est pourquoi nous avons sensibilisé l’ensemble des configurateurs d’utiliser le tag « Prod” à bon escient, ils connaissent désormais la contrainte de cold start et acceptent facilement la lenteur de ~1 min sur la première exécution le matin.
Le gain cumulé sur les deux actions effectuées quasi en même temps (axe 3 et 4 cumulé) ont permis de descendre de ~27 machines en équivalent temps plein en août à ~17 machines en équivalent temps plein au mois de novembre. Cela permet un gain d’un peu plus de 35% par rapport à août.
#5 Extinction totale des plateformes de développement la nuit
Certaines de nos plateformes sont dédiées au développement ou à l’intégration continue.
Ces plateformes ne sont sollicitées que lors des heures ouvrés. Ici, mieux que d’optimiser le scaling on peut imaginer en axe d’amélioration pouvoir éteindre voir même supprimer complètement ces environments.
C’est une solution qui parait évidente mais nous éteignons maintenant certaines plateformes inactives pour correspondre à notre rythme de travail sur les heures et jours ouvrés.
Aujourd’hui certains éléments essentiels de ces plateformes ne sont pas encore déployés via l’infrastructure as code, ce qui signifie que remettre en place ces plateformes le matin nécessite quelques actions manuelles que nous ne souhaitons pas assumer quotidiennement. Il nous est donc compliqué pour l’instant de profiter de ce levier.
Nos efforts vont dans ce sens afin de pouvoir activer ce levier courant du premier semestre 2023.
Clés de compréhension
Kubernetes : il s’agit d’un orchestrateur de container. Il est au container ce que l’hyperviseur est aux VM. Ce système est connu depuis 2015 et maintenant largement utilisé sur des environnements de productions sur toutes les typologies d’entreprise.
Container : Un container est un packaging applicatif qui à la particularité de ne contenir qu’un seul et unique processus applicatif et les librairies uniquement nécessaires à son fonctionnement. Sa surface d’exposition aux vulnérabilités cyber est donc limitée, son poids en Mo plutôt léger, son fonctionnement simple et sa gestion agile. Ce packaging est finalement assez frugal par nature. Dans le monde de Kubernetes, on parle plus souvent de pods.
Pods : c’est un groupement de 1 à plusieurs containers partageant les mêmes caractéristiques réseau. Les autres composants le reconnaissent comme une entité unique. Pour s’instancier, un pod a besoin de ressources disponibles sur le cluster.
Cluster : Il s’agit du chef d’orchestre principal sur lequel les Pods applicatifs viennent s’instancier. On parle de cluster kubernetes car c’est effectivement un cluster de Nodes. Ajouter un cluster permet d’être plus résilient notamment si Node crash car les autres continueront de fonctionner.
Nodes : machines physiques ou virtuelles exploitées par le cluster pour y distribuer les pods applicatifs. Il s’agit d’un “stock” de CPU et de RAM.
Horizontal Pod AutoScaling (HPA) : Les pods peuvent être multipliés pour assurer la résilience du service ou bien un pic de charge. Supposons qu’un pod est capable de traiter 3 requêtes par seconde, si le service subit un pic de charge à 8 requêtes par seconde, l’Horizontal Pod Scaling est le système qui portera le nombre de pod à 3 afin d’assumer le pic.
Cluster Autoscaling (CA) : Là où le HPA met à l’échelle le nombre de Pod, le CA met à l’échelle le nombre de Nodes. Si nous manquons de place sur le cluster pour accueillir de nouveaux pods, ce système requiert directement auprès de Scaleway de nouveaux nodes.
PUE : Power Usage Effectiveness , est le rapport entre l’énergie totale consommée par un Datacenter et l’apport utile d’énergies aux machines.
Avec un PUE de 1,15 , pour 1 mégaWatt utile aux machines je dois fournir 0,15 mégaWatt pour le refroidissement ainsi que le fonctionnement du bâtiment



