
Green Tech, Tech for Good, Tech'Care... There are many ways to talk about the impacts that new technologies have on our carbon balance, as well as list potential solutions. With more than 53% of greenhouse gas emissions generated by the digital sector, data centers and network infrastructures consume as much as we use data. Although running with untrained AI drastically reduces this impact, discover 5 solutions related to data processing and storage that are changing our paradigms.
#1 Choosing an eco-friendly cloud
The "Green" approach to IT requires applying environmentally friendly practices directly at the infrastructure level. The choices of technology usage are decisive in the environmental impact you will have.
Scaleway: a provider with favorable energy efficiency
In our case, Kubernetes clusters are managed by a trusted cloud provider: ScalewayIt is through this cloud provider that we consume IT resources, delegating the management of physical servers (power, cooling, device management, etc.). Scaleway offers us a data center here with an "adiabatic" cooling system that does not require air conditioning, which allows this data center to display a remarkable PUE (Power Usage Effectiveness) of 1.15.
Exploiting the possibilities of infrastructure on demand
We consume the resources necessary "for use" and have the capacity, and even the responsibility, to make the resources that we do not use available to other Scaleway customers. The approach is simple: consume only what is needed, or as close as possible to that need, and avoid unnecessary load on the machines of Golem.ai, not only from a financial point of view of course but also from an environmental point of view.
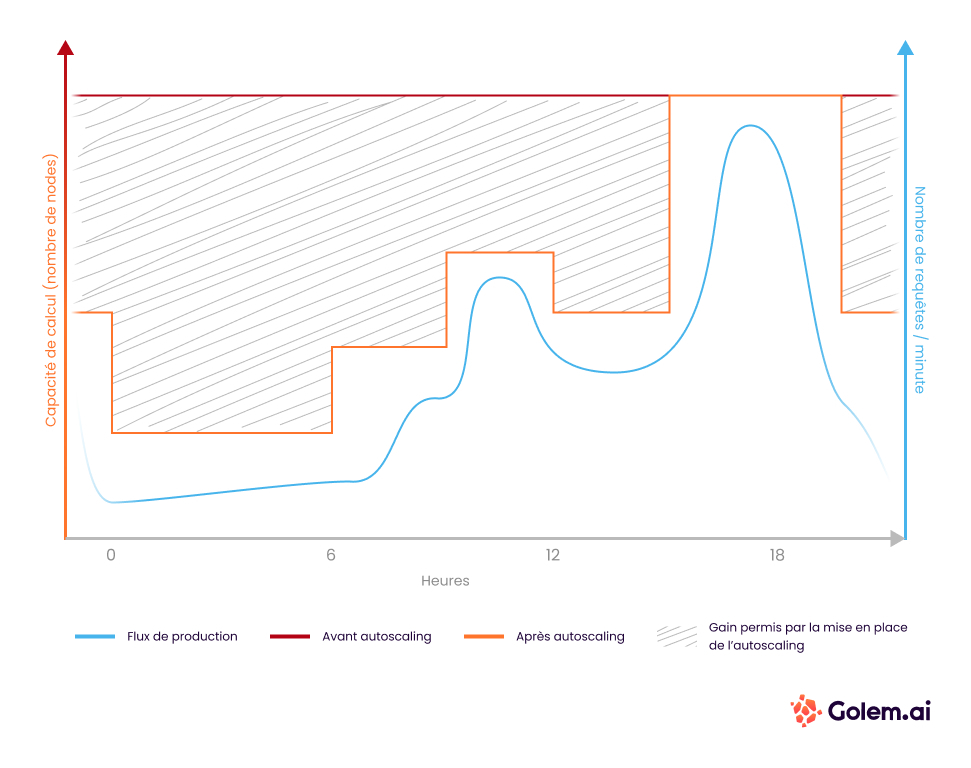
#2 Setting up automatic scaling with Keda
Before modifying our organizational mode to ensure possible load peaks, our platform was dimensioned 24/7 to values that could handle potential load peaks. With this setup, our performance was good, but we had a bitter taste in view of the waste we were causing. This meant that machines were allocated and powered up but unexploited during our off-peak hours.
To solve this, the idea was quite simple: exploit the combined possibilities of Horizontal Pod AutoScaling, Cluster Autoscaling and Keda to ensure the provisioning of resources not in a constant and high manner, but in response to demand, in order to always have production volume as close to demand as possible.
Thanks to this method, between June and August 2022, we went from a full-time consumption of 56 production machines to 27 production machines. We therefore reduced the use of machines on the production platform by half."
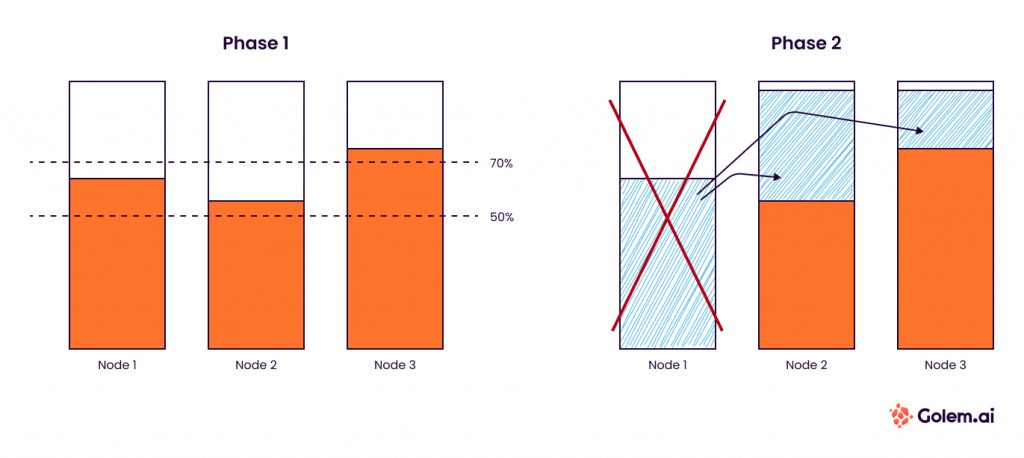
#3 Increasing the level of cluster kubernetes filling
As previously seen, the cluster autoscaler makes the decision to remove a node from the cluster from a certain "non-use" threshold. By default, this is 50%. This choice is very secure as it allows, in the case of a 2-node cluster, to almost guarantee that the second node can assume all the load alone.
This configuration makes sense for clusters with few nodes for resilience reasons. At Golem.ai, we are in a more complex configuration with a node evolution ranging from 14 for off-peak periods and 55 for peak periods. At this scale, the margin per node can be reduced because the total margin remains high.
#4 Heightening awareness to users for responsible use of the platform
Our platform currently has two types of users:
- End customers who use the service for its functional promise
- Configurators (employees of the company or directly from Golem.ai) who use the platform to adjust the AI configurations that consume this service in a more random and less predictable way
C’est pourquoi nous avons intégré un système de tags permettant d’isoler ces deux usages. Le premier usage est appelé “Prod” et le nombre de réplica minimal est de 5 pods pour ces intelligences artificielles. Le second cas d’usage est appelé “Hors prod” avec un nombre de réplica allant de 1 jusqu’à 0 la nuit. C’est ce qu’on appelle le “scale down to 0”(0 pod).
This organization directly impacts performance. The "Prod" situations have resources in advance, which allows the system to respond directly, with good velocity, and to adapt to peak loads during the day. The "Off-prod" situations, on the other hand, are less reactive, especially if no pods are available at the time of the request. If the artificial intelligence has not been solicited for a while, it has a provisioning time of about 1 minute. A recurrent delay that occurs every morning that is encountered by configurators. Finally, at Golem.ai, we reproduce the mode of operation of the so-called serverless cloud offers for our AI, so we inherit its main constraint commonly called the cold start.
Some configurators do not use this tagging system correctly to benefit from the scale down to 0, or they have noticed that the "Prod" tag is more reactive and they use it more regularly. That's why we have sensitized all configurators to use the "Prod" tag wisely, and they now know the cold start constraint and easily accept the slowness of ~1min on the first execution in the morning.
The cumulative gain on the two actions performed almost at the same time (axis 3 and 4 combined) allowed us to go from ~27 machines in full-time equivalent in August to ~17 machines in full-time equivalent in November. This represents a gain of a little more than 35% compared to August.
#5 Total shutdown of development platforms at night
Some of our platforms are dedicated to development or continuous integration.
These platforms are only solicited during business hours. Here, better than optimizing scaling, we can imagine an improvement axis to be able to turn off or even completely remove these environments.
It is an obvious solution but we now turn off some inactive platforms to match our work schedule during business hours and days.
Today, some essential elements of these platforms are not yet deployed via infrastructure as code, which means that reinstating these platforms in the morning requires some manual actions that we do not want to perform on a daily basis. It is therefore complicated for us at the moment to take advantage of this lever.
Our efforts are going in this direction to be able to activate this lever during the first half of 2023.
Key concepts:
Kubernetes a container orchestrator. It is to contain what the hypervisor is to VMs. This system has been known since 2015 and is now widely used in production environments in all types of companies.
Container an application packaging that has the particularity of containing only one application process and the libraries necessary for its operation. Its surface of exposure to cyber vulnerabilities is therefore limited, the weight in Mo rather light, its operation is simple and its management agile. This packaging is ultimately quite frugal by nature. In the Kubernetes world, we speak more often of Pods.
Pods a grouping of 1 to several containers sharing the same network characteristics. The other components recognize it as a unique entity. To instantiate, a Pods needs resources available on the cluster.
Cluster the main orchestrator on which the application Pods come to instantiate. We speak of the kubernetes cluster because it is a cluster of Nodes. Adding a cluster allows it to be more resilient especially if Node crashes because the others will continue to function.
Nodes physical or virtual machines operated by the cluster to distribute the application pods. It is a "stock" of CPU and RAM.
Horizontal Pod AutoScaling (HPA) Pods can be multiplied to ensure service resilience or a spike in traffic. Let's say a pod can handle 3 requests per second. If the service experiences a spike in traffic at 8 requests per second, Horizontal Pod Scaling is the system that will increase the number of pods to 3 to handle the spike.
Cluster Autoscaling (CA) Where HPA scales the number of Pods, CA scales the number of Nodes. If we run out of space on the cluster to accommodate new pods, this system directly requests new nodes from Scaleway.
PUE Power Usage Effectiveness is the ratio between the total energy consumed by a Data Center and the useful energy supplied to the machines.
With a PUE of 1.15, for 1 megaWatt useful to the machines, one must provide 0.15 megaWatt for cooling and building operation.



