
The efficiency and reliability of artificial intelligence systems are at the heart of the current concerns of more and more companies. Two essential measures stand out: the relevance calculation, and the confidence score. They play a crucial role in evaluating these systems. Moreover, they offer varied and complementary perspectives on the performance of AI models. This article aims to detail each of these measures, highlighting their use cases and uses.
The calculation of relevance
To calculate the relevance of an AI, several scores are distinguished: score f1, score f2, or any other F-beta family are an example.
Pour expliquer ces scores-ci, prenons un exemple de classification. Imaginons que nous demandions à notre intelligence artificielle d’attribuer une catégorie ou plusieurs à une donnée.
ForInboxCare at Golem.ai this data may be:
- a message where each category represents one or more expressed intentions (complaints, request for quotation, document request, etc.)
- an attachment where each category represents the type of document (proof of identity, contract, quote, order, etc.)
- extracted information contained in a message or attachment (phone number, order number, address, etc.)
Scope : Three possible values A, B or C representing possible intentions received in a message. Messages may contain one or more intentions.
| Given values by AI | Expected values | True Positive | True Negative | False Positive | False Negative |
|---|---|---|---|---|---|
| A | AB | 1 | 1 | 1 | |
| AB | AB | 2 | 1 | ||
| – | AB | 1 | 2 | ||
| C | AB | 1 | 2 |
Let’s work step by step, and explain the notions of true positive, true negative, false positive, false negative, as well as the notions of precision and recall/sensitivity.
True positive (tp): I waited, I had
True negative (tn) : I didn't wait, i didn't have
False positive (fp) : I didn't wait, I had
False negative (fn) : I waited, I didn't have
Precision : The given category is correct. If you are answered, that is correct.
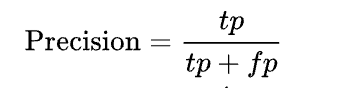
For example: I am a teacher of a class of 150 students, I want the AI to give me the names of all those who have had 16/20 exactly. Well the accuracy will be the ability of the AI to give X times the correct answer, i.e., “16/20”. Let’s say the accuracy score is 80%, that means that 8 times out of 10 the AI gives me the name of someone who has had 16/20, and 2 times the AI gives me the name of people who have not had 16/20. The peculiarity is that here, we will have all the names of people who had 16/20 in the class, but also with names that have not had 16/20.
Recall / Sensibilité : We detect enough of what is expected.

Let’s take the example of the class of 150 students, recall means the fact that AI will give a good answer overall, that is to say give me the name of someone who had 16/20. The peculiarity here is that we will not however have all the names having had 16/20 in the class.
To differentiate these two parameters, precision quantifies the fact that the AI response is correct, while recall/sensitivity refers to the fact that overall, what is given by the AI is correct.
You need to understand accuracy and recall to understand the formula of F1 score and F2 score.
F-beta scoring formulas
The F-beta score (Fβ) is a statistical measure used in machine learning to evaluate the performance of a classification model, especially in situations where the balance between accuracy (precision) and sensitivity (recall) is important and may require adjustment based on specific needs.
The F-beta score is a weighted harmonic mean of accuracy and sensitivity, where a parameter β is used to determine the relative weight given to recall versus precision :
- If β > 1, the score gives more weight to recall, which is useful in situations where false negatives (not detecting a real positive case) are more problematic than false positives.
- If β < 1, the score puts more emphasis on precision, which is appropriate when false positives (wrongly identifying a negative case as positive) are of greater concern.
- If β = 1, this leads to the F1 score, which gives equal importance to precision and recall.
Therefore, depending on the needs of a company, one of these two scores would be wiser to favor. If a company needs an AI with a good precision rate such as a good recall rate, the F1 score is preferred, if a company needs an AI to perform very well in recall but not necessarily in precision, the f2 score is preferred.
With InboxCare, the problem is much more complicated than finding only the names of those who had 16/20. Indeed, InboxCare allows the extraction of information, the categorization of attachments, and the categorization of incoming messages.
This data is often used by our customers to automate processes such as the enrichment or updating of customer records through information/ documents received, automatic filling of forms.
At Golem.ai, we favour the F1 score because for the use cases of our customers, it is necessary to have a balance between a good precision rate and a good recall rate.
Moreover, there is a question about the automation of these processes that are processed by other information systems: How to ensure that the AI process is accurate in real time? If a false positive is sent to an automation system, what will the impacts be? It is in this case that we seek with our customers to minimize this scenario.
This is where the confidence score comes in.
Confidence score
The confidence score is also a measure of AI performance. Where we seek to measure the relevance of our AI through tests where the expected result is pre-defined.
The trust score will attempt to define the “trust” the algorithm has in its response when rendering.
Worded differently:
- Relevance: We observe that AI responds correctly to outcomes we have defined
- confidence: AI seems confident in the veracity of its response
The complexity of this score is that it is particularly difficult to predict this confidence. If we were able to do so, artificial intelligence would never again make mistakes in any field of application.
At Golem.ai, the relevance rate is on average 87% on an F1 score, so the issue of trust is quite low. But we are now working to add this confidence score to meet the expectations of our customers on an increasing demand for post-Inboxcare automation.
Several approaches are under study but we rely on the explainability of our AI by comparing the detailed results of our AI and the content of each message from our test sets to the result and content of the message processed by our NLU to determine if the outcome is consistent.
“If the result is a category A and the content of the message as well as the explanation of this result of our NLU resembles the message content that we know and that are really category A then we feel that our confidence in the result is high”
It is essential to emphasize that these different performance indicators should not be contrasted, but rather used wisely according to their specificities and the specific needs of each company. The F1 and F2 scores, although similar, are distinguished by their respective weighting of accuracy and recall. The choice between these two measures depends on the company’s priorities: a balance between accuracy and recall for the F1 score, or an increased importance of recall for the F2 score.
On the other hand, the confidence score offers a different perspective, assessing the probability that an AI response is correct based on its database. Therefore, it is important to note that the f1 score, and the f2 score are a measure based on a context where the result is defined, while the confidence score is a real-time measure of an AI. It is generally less reliable than a score that is based on predefined results.
Thus, each of these indicators brings a different light on the performance of an AI system, and their joint use allows a more complete and nuanced evaluation.



