
L’efficacité et la fiabilité des systèmes d’intelligence artificielle sont au cœur des préoccupations actuelles de plus en plus d’entreprises. Deux mesures essentielles se distinguent : le calcul de la pertinence, et le score de confiance. Elles jouent un rôle crucial dans l’évaluation de ces systèmes. Plus encore, elles offrent des perspectives variées et complémentaires sur la performance des modèles d’IA. Cet article se propose de détailler chacune de ces mesures, en soulignant leurs cas d’usages et leurs utilisations.
Le calcul de la pertinence
Pour calculer la pertinence d’une IA, plusieurs scores se distinguent : score f1, score f2, ou tout autre de la famille des F-beta en sont un exemple.
Pour expliquer ces scores-ci, prenons un exemple de classification. Imaginons que nous demandions à notre intelligence artificielle d’attribuer une catégorie ou plusieurs à une donnée.
Dans le cas d’InboxCare chez Golem.ai cette donnée peut être:
- un message où chaque catégorie représente une ou plusieurs intentions exprimées (réclamations, demande de devis, demande de document etc.)
- une pièce-jointe où chaque catégorie représente le type de document (justificatif d’identité, contrat, devis, commande etc)
- un information extraite contenue dans un message ou une pièce-jointe (numéro de téléphone, numéro de commande, adresse etc)
Périmètre : Trois valeurs possibles A, B ou C représentant des intentions possibles reçues dans un message. Les messages peuvent contenir une ou plusieurs intentions.
| Valeurs données par l’IA | Valeurs attendues | True Positive | True Negative | False Positive | False Negative |
|---|---|---|---|---|---|
| A | AB | 1 | 1 | 1 | |
| AB | AB | 2 | 1 | ||
| – | AB | 1 | 2 | ||
| C | AB | 1 | 2 |
Fonctionnons étape par étape, et expliquons les notions de true positive, true negative, false positive, false negative, ainsi que les notions de précision et de recall/sensibilité.
True positive (tp) : j’ai attendu, j’ai eu
True negative (tn) : j’ai pas attendu, j’ai pas eu
False positive (fp) : j’ai pas attendu, j’ai eu
False negative (fn): j’ai attendu, j’ai pas eu
Précision : La catégorie donnée est juste. Si on vous répond, c’est correct.
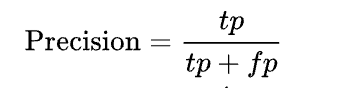
Par exemple : Je suis professeur d’une classe de 150 élèves, je veux que l’IA me donne le nom de tous ceux qui ont eu 16/20 exactement. Et bien la précision sera la capacité de l’IA à donner X fois la bonne réponse, soit “16/20”. Imaginons que le score de précision soit à 80%, cela veut dire que 8 fois sur 10 l’IA me donne le nom de quelqu’un qui a eu 16/20, et 2 fois l’IA me donne le nom de personnes n’ayant pas eu 16/20. La particularité est qu’ici, on aura tous les noms des personnes ayant eu 16/20 dans la classe, mais avec également des noms n’ayant pas eu 16/20.
Recall / Sensibilité : On détecte suffisamment de ce qui est attendu.

Reprenons l’exemple de la classe de 150 élèves, la sensibilité désigne le fait que l’IA va globalement donner une bonne réponse, c’est-à-dire me donner le nom de quelqu’un qui a eu 16/20. La particularité ici est que nous n’aurons pas toutefois l’entièreté des noms ayant eu 16/20 dans la classe.
Pour bien différencier ces deux paramètres, la précision quantifie le fait que la réponse par l’IA soit correcte, tandis que le recall/sensibilité désigne le fait que globalement, ce qui est donné par l’IA est correcte.
Il faut bien comprendre ce qu’est la précision et le recall pour comprendre la formule du score F1 et du score F2.
Formules du score F-beta
Le score F-beta (Fβ) est une mesure statistique utilisée en apprentissage automatique pour évaluer la performance d’un modèle de classification, en particulier dans les situations où la balance entre précision (précision) et sensibilité (recall) est importante et peut nécessiter un ajustement en fonction de besoins spécifiques.
Le score F-beta est une moyenne harmonique pondérée de la précision et de sensibilité, où un paramètre β est utilisé pour déterminer le poids relatif donné à la sensibilité par rapport à la précision :
- Si β > 1, le score donne plus de poids à la sensibilité, ce qui est utile dans les situations où les faux négatifs (ne pas détecter un cas positif réel) sont plus problématiques que les faux positifs.
- Si β < 1, le score met davantage l’accent sur la précision, ce qui est approprié lorsque les faux positifs (identifier à tort un cas négatif comme positif) sont plus préoccupants.
- Si β = 1, cela mène au score F1, qui attribue une importance égale à la précision et à la sensibilité.
Dès lors, en fonction des besoins d’une entreprise, un de ces deux scores serait plus judicieux à privilégier. Si une entreprise a besoin d’une IA ayant un bon taux de précision comme un bon taux de recall, le score F1 est à privilégier, si une entreprise a besoin qu’une IA soit très performante en recall mais pas nécessairement en précision, le score f2 est à privilégier.
Avec InboxCare, la problématique est bien plus compliquée que de ne trouver seulement les noms de ceux qui ont eu 16/20. En effet, InboxCare permet l’extraction d’informations, la catégorisation de pièces jointes, et la catégorisation des messages entrants.
Ces données sont souvent employées par nos clients pour automatiser des processus tels que l’enrichissement ou la mise à jour des dossiers clients grâce aux informations/documents reçus, remplissage automatique de formulaires.
Chez Golem.ai, nous privilégions ainsi le score F1 car pour les cas d’usages de nos clients, il est nécessaire d’avoir un équilibre entre un bon taux de précision et un bon taux de recall.
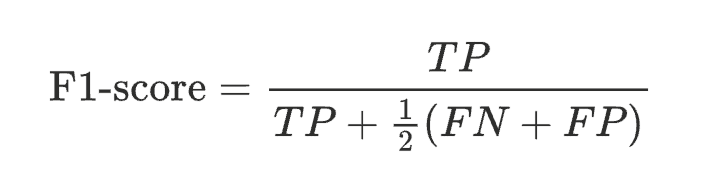
Plus encore, une question se pose sur l’automatisation de ces processus qui sont traités par d’autres systèmes d’information : Comment s’assurer que le processus de l’IA soit précis en temps réel? Si un faux positif est envoyé à un système d’automatisation quels seront les impacts? C’est dans ce cas de figure que nous cherchons avec nos clients à réduire au maximum ce cas de figure.
C’est là que le score de confiance intervient.
Le score de confiance
Le score de confiance est également une mesure de performances de l’IA. Là où nous cherchons à mesurer la pertinence de notre IA via des tests où le résultat attendu est pré-défini.
Le score de confiance tentera de définir la “confiance” qu’a l’algorithme en sa réponse lors de son rendu.
Formulé différemment :
- pertinence : Nous observons que l’IA répond correctement à des résultat que nous avons défini
- confiance : L’IA semble confiante dans la véracité de sa réponse
La complexité de ce score est qu’il est particulièrement difficile de prédire cette confiance. Si nous en étions capables, l’intelligence artificielle ne ferait plus jamais d’erreur quel que soit son domaine d’application.
Chez Golem.ai, le taux de pertinence est en moyenne de 87% sur un score F1, la problématique de confiance est donc assez faible. Mais nous travaillons aujourd’hui à ajouter ce score de confiance afin de répondre aux attentes de nos clients sur une demande de plus en plus grande d’automatisation post-Inboxcare.
Plusieurs approches sont à l’étude mais nous nous appuyons sur l’explicabilité de notre IA en effectuant une comparaison entre les résultats détaillés de notre IA et le contenu de chaque message provenant de nos sets de test au résultat et contenu du message traité par notre NLU afin de déterminer si le résultat est cohérent.
“Si le résultat est une catégorie A et que le contenu du message ainsi que l’explication de ce résultat de notre NLU ressemble au contenu de message que nous connaissons et qui sont réellement de catégorie A alors nous estimons que notre confiance dans le résultat est élevé”
Il est primordial de souligner qu’il ne faut pas mettre en opposition ces différents indicateurs de performance, mais plutôt de les utiliser judicieusement en fonction de leurs spécificités et des besoins spécifiques de chaque entreprise. Les scores F1 et F2, bien que similaires, se distinguent par leur pondération respective de la précision et du recall. Le choix entre ces deux mesures dépend des priorités de l’entreprise : un équilibre entre précision et recall pour le score F1, ou une importance accrue du recall pour le score F2.
D’autre part, le score de confiance offre une perspective différente, en évaluant la probabilité qu’une réponse donnée par l’IA soit correcte en se basant sur sa base de données. Dès lors, il est important de noter que le score f1, et le score f2 sont une mesure basée sur un contexte où le résultat est défini, tandis que le score de confiance est quant à lui une mesure en temps réel d’une IA. Il est en général moins fiable que qu’un score qui est basé sur des résultats prédéfinis.
Ainsi, chacun de ces indicateurs apporte une lumière différente sur la performance d’un système d’IA, et leur utilisation conjointe permet une évaluation plus complète et nuancée.



