
Why Golem.ai decided to experiment with LLMs ?
At Golem.ai, we believe in the complementary nature of Symbolic & Generative AI approaches.
The first episode of this series of articles explains this.
We invite you to take a look if you haven't already.
Why choose LlaMA-2 ?
Facebook parent company Meta caused a stir in the artificial intelligence (AI) industry last July with the launch of LLaMA 2, an open-source large-scale language model (LLM) designed to challenge the restrictive practices of its major technological competitors.
Unlike AI systems launched by Google, OpenAI and others (such as Apple with Apple GPT?), which are tightly guarded in proprietary models, Meta is releasing LLaMA 2's code and data free of charge to enable researchers worldwide to build and improve the technology !
Here are the five key features of Llama 2:
- Llama 2 outperforms other open-source LLMs in benchmarks for reasoning, coding proficiency, and knowledge tests.
- The model was trained on almost twice the data of version 1, totaling 2 trillion tokens. Additionally, the training included over 1 million new human annotations and fine-tuning for chat completions.
- The model comes in three sizes, each trained with 7, 13, and 70 billion parameters.
- Llama 2 supports longer context lengths, up to 4096 tokens.
- Version 2 has a more permissive license than version 1, allowing for commercial use.
First tests inpracticing & learning mode” avec Replicate.com
To Test Llama-2, we first opted for Replicate.com
This allows you to pay as you go, with no need to install on existing hardware.
A perfect first approach for experimenting !
However, for reasons of privacy and economic intelligence, we’ve opted for a second approach, as explained below.
Why Llama-2 on in-house GPUs after Replicate.com ?
At Golem.ai, Trusted artificial intelligence, data sovereignty, security and control of the entire value chain is the most important thing.
For this reason, we decided to carry out our own benchmark using the materiel resources of our French Cloud Provider Scaleway.
Although the LLaMA-2 model is free to download and use, it should be noted that self-hosting of this model requires GPU power for timely processing.
LLaMA 2 is available in three sizes: 7 billion, 13 billion and 70 billion parameters, depending on the model you choose.
For the purposes of this demonstration, we will use model 70b to obtain the best relevance !
Setting up the in-house GPUs solution
Let’s get to the heart of the matter 😈
Integration overview
- The user provides one input: a prompt input (i.e. ask a question).
- An API call is made to the LLAMA.CPP server, where the prompt input is submitted and the response generated by Llama-2 is obtained and displayed to the user.
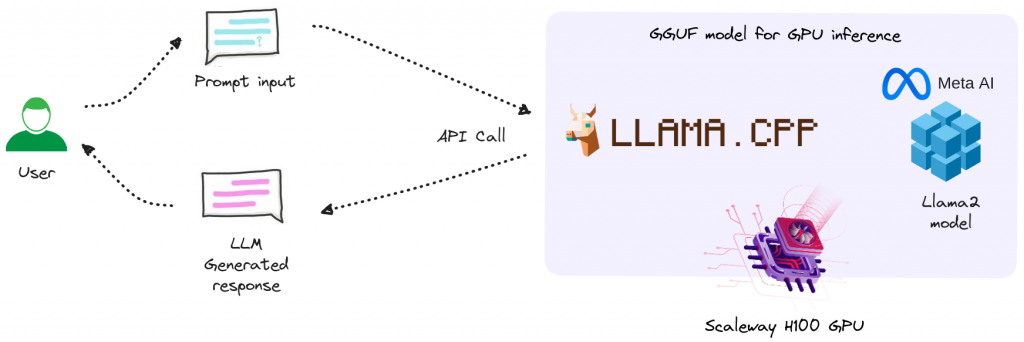
We running Llama-2 70B model using llama.cpp, with NVIDIA CUDA 12.2 on Ubuntu 22.04
Llama.cpp is a C/C++ library for the inference of LlaMA/LlaMA-2 models.
For this scenario, we will use the H100-1-80G, the most powerful hardware in the GPUs range from our French Cloud provider Scaleway.
Scaleway's GPU range comprises four products dedicated to different uses 🚀
| Machine | GPU | Mémoire GPU (VRAM) | Processeur | Coeurs physiques (vCPU) | RAM |
|---|---|---|---|---|---|
| Render-S | Dedicated NVIDIA Tesla P100 16GB PCIe | 16GB CoWoS HBM2 | Intel Xeon Gold 6148 cores | 10 | 42 GB |
| H100-1-80G | H100 PCIe Tensor Core GPU | 80GB(HBM2e) | AMD EPYC™ 9334 | 24 | 240 GB |
| H100-2-80G | 2x H100 PCIe Tensor Core GPU | 2x 80GB(HBM2e) | AMD EPYC™ 9334 | 48 | 480 GB |
The method for implementing the solution is specified in the next few lines.
We estimate that it will take around 30mn to set up, provided you meet our OS, software, hardware requirements and you don’t encounter any errors 🙂
A. Installation
Two possible paths :
1. The official way to run LLaMA-2 is via their examples repository and in their recipes repository
- Benefits :
- Official method
- Disadvantages
- Developed in python (Slow to run & Excessive RAM consumption)
- Dysfonctionnement de l’accélération GPU H100
2. Run LLaMA-2 via the llama.cpp interface
- Benefits :
- This pure C/C++ implementation is faster and more efficient than its official Python counterpart, and supports GPU acceleration via CUDA and Apple's Metal. This considerably speeds up inference on the CPU and makes GPU inference more efficient.
- Disadvantages
- Community-based method (unofficial)
We've opted to use llama.cpp for this implementation.
B. Model available
Check model type :
https://www.hardware-corner.net/llm-database/Llama-2/
/!\ /!\ llama.cpp no longer supports the GGML models
https://huggingface.co/TheBloke/Llama-2-70B-Chat-GGML
⇒ Replace with GGUF models
https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF (based on Llama-2-70b-chat-hf)
C. Installation process
- Install NVIDIA CUDA DRIVER (if not installed on your GPU Machine)
To start, let's install NVIDIA CUDA on Ubuntu 22.04. The guide presented here is the same as the CUDA Toolkit download page provided by NVIDIA.
$ wget <https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb>
$ sudo dpkg -i cuda-keyring_1.1-1_all.deb
$ sudo apt-get update
$ sudo apt-get -y install cuda-toolkit-12-3
After installing, the system should be restarted. This is to ensure that NVIDIA driver kernel modules are properly loaded with dkms. Then, you should be able to see your GPUs by using nvidia-smi.
$ sudo shutdown -r now
llm@h100-ftw:~$ nvidia-smi
Wed Oct 4 08:44:54 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.104.12 Driver Version: 535.104.12 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA H100 PCIe On | 00000000:01:00.0 Off | 0 |
| N/A 42C P0 51W / 350W | 4MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+2. Make sure you have the nvcc binary in your path
llm@h100-ftw:~$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Tue_Aug_15_22:02:13_PDT_2023
Cuda compilation tools, release 12.2, V12.2.140
Build cuda_12.2.r12.2/compiler.33191640_0
*if the command can’t be found : ln -s /usr/local/cuda/bin/ /bin/3. Clone and Compile llama.cpp
After installing NVIDIA CUDA, all of the prerequisites to compile llama.cpp are already satisfied. We simply need to clone llama.cpp and compile.
$ git clone <https://github.com/ggerganov/llama.cpp>
$ cd llama.cpp
For matching CUDA arch and CUDA gencode for various NVIDIA architectures :
Modify Makefile before compilation with NVCCFLAGS += -arch=all-major instead of NVCCFLAGS += -arch=native
$ make
$ make clean && LLAMA_CUBLAS=1 make -j
4. Download and Run LLaMA-2 70B
We use the converted and quantized model by the awesome HuggingFace community user, TheBloke. The pre-quantized models are available via this link . In the model repository name, GGUF refers to a new model file format introduced in August 2023 for llama.cpp.
To download the model files, first we install and initialize git-lfs.
$ sudo apt install git-lfs
$ git lfs install
You should see "Git LFS initialized." printed in the terminal after the last command. Then, we can clone the repository, only with links to the files instead of downloading all of them.
cd models
GIT_LFS_SKIP_SMUDGE=1 git clone <https://huggingface.co/TheBloke/Llama-2-70B-chat-GGUF>
$ cd Llama-2-70B-GGUF
$ git lfs pull --include llama-2-70b-chat.Q6_K.gguf-split-a
$ git lfs pull --include llama-2-70b-chat.Q6_K.gguf-split-b
$ cat llama-2-70b-chat.Q6_K.gguf-split-* > llama-2-70b-chat.Q6_K.gguf && rm llama-2-70b-chat.Q6_K.gguf-split-*
The one file we actually need is llama-2-70b-chat.Q6_K.gguf, which is the Llama 2 70B model processed using one of the 6-bit quantization method.
This model requires an average of 60GB of memory. On the H100, we’ve 80GB(HBM2e) of VRAM. Processing will be carried out entirely on the H100 GPU !

$ ./main -ngl 100 -t 1 -m llama-2-70b-chat.Q6_K.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "[INST] <<SYS>>\\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\\n<</SYS>>\\n{prompt}[/INST]"
5. Serving Llama-2 70B
Many useful programs are built when we execute the make command for llama.cpp.
main is the one to use for generating text in the terminal.
perplexity can be used for compute the perplexity against a given dataset for benchmarking purposes.
In this part we look at the server program, which can be executed to provide a simple HTTP API server for models that are compatible with llama.cpp.
https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md
$ ./server -m models/Llama-2-70B-chat-GGUF/llama-2-70b-chat.Q6_K.gguf \\
-c 4096 -ngl 100 -t 1 --host 0.0.0.0 --port 8080
Replace -t 32 with the number of physical processor cores. For example, if the system has 32 cores / 64 threads, use -t 32. If you're completely offloading the model to the GPU, use -t 1 (as on the H100).
Replace -ngl 80 with the number of GPU layers for which you have VRAM (such as H100). Use -ngl 100 to unload all layers onto VRAM - if you have enough VRAM. Otherwise, you can partially offload as many layers as you have VRAM for, onto one or more GPUs.
params : https://huggingface.co/TheBloke/Llama-2-70B-Chat-GGML#how-to-run-in-llamacpp
llm_load_tensors: ggml ctx size = 0.23 MB
llm_load_tensors: using CUDA for GPU accelerationllm_load_tensors: mem required = 205.31 MB
llm_load_tensors: offloading 80 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 83/83 layers to GPU
llm_load_tensors: VRAM used: 53760.11 MB
...................................................................................................
llama_new_context_with_model: n_ctx = 4096
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: offloading v cache to GPU
llama_kv_cache_init: offloading k cache to GPU
llama_kv_cache_init: VRAM kv self = 1280.00 MB
llama_new_context_with_model: kv self size = 1280.00 MB
llama_new_context_with_model: compute buffer total size = 573.88 MB
llama_new_context_with_model: VRAM scratch buffer: 568.00 MB
llama_new_context_with_model: total VRAM used: 55608.11 MB (model: 53760.11 MB, context: 1848.00 MB)
Explanation of Llama.cpp metrics :
When you execute your input, various metrics are communicated to you to measure its performance.
llama_print_timings: load time = 59250.72 ms
llama_print_timings: sample time = 611.28 ms / 180 runs ( 3.40 ms per token, 294.47 tokens per second)
llama_print_timings: prompt eval time = 1597.63 ms / 508 tokens ( 3.14 ms per token, 317.97 tokens per second)
llama_print_timings: eval time = 11703.38 ms / 179 runs ( 65.38 ms per token, 15.29 tokens per second)
llama_print_timings: total time = 13958.06 ms
- load time: loading model file
- sample time: generating tokens from the prompt/file choosing the next likely token.
- prompt eval time: how long it took to process the prompt/file by LLaMa before generating new text.
- eval time: how long it took to generate the output (until
[end of text]or the user set limit). - total: all together
Benchmark between Replicate.com and NVidia H100 GPUs hosted by Scaleway
After running a hundred tests in total between Replicate.com et le H100 de Nvidia hébergé par Scaleway, nous concluons que la différence d’exécution est de 40 % en faveur de l’utilisation des GPU H100-1-80G fournis par Scaleway.
The Hallucination Score on a scale of 0 to 3 that we assign at Golem.ai, which represents the relevance of the response to each test, is not sufficiently representative of any notable difference between Replicate.com and Scaleway.
To find out more, we invite you to read the article on protocole de test LLM de Golem.ai
Conclusion & Opening
The use cases go far beyond this first experiment. At Golem.ai, we believe there are many other ways to use LLMs with our technology, including tooling and support for our users.
This is just the beginning of a long and exciting adventure.
There are several Frameworks for Serving LLMs. Each has its own features.
In this article, we experimented with Llama.cpp running LLaMa 70b model.
To learn more about this topic, please read the following article, which deals specifically with this subject.



