
L’explosion de l’usage des réseaux de neurones artificiels, technique de machine learning facile d’accès et applicable à presque tout problème, a fait émerger un rapport nouveau aux algorithmes. Quel que soit le problème, l’expert et même le logiciel lui-même ne sont plus en cause ; c’est la faute à la data.

Thomas SOLIGNAC, CEO de Golem.ai
L’IA est une grande famille
De toutes les techniques de Machine Learning, le réseau de neurones artificiels est certainement la plus populaire ces derniers temps, à tel point que “Machine Learning” est maintenant utilisé comme synonyme de “Réseaux de Neurones Artificiels” par beaucoup. À tort, bien sûr.
Alors qu’il était déjà souvent coutume d’assimiler l’IA au Machine Learning, l’IA se voit maintenant amalgamée aux réseaux de neurones artificiels. Assurément, ces dernières années ont déplumé l’IA de sa richesse au profit d’un vocabulaire très limité.
En réalité, depuis ses débuts, l’IA se développe à travers 2 approches : l’approche symbolique et l’approche connexionniste. Le Machine Learning s’inscrit dans cette dernière approche, et se décline lui-même en plusieurs types catégories.
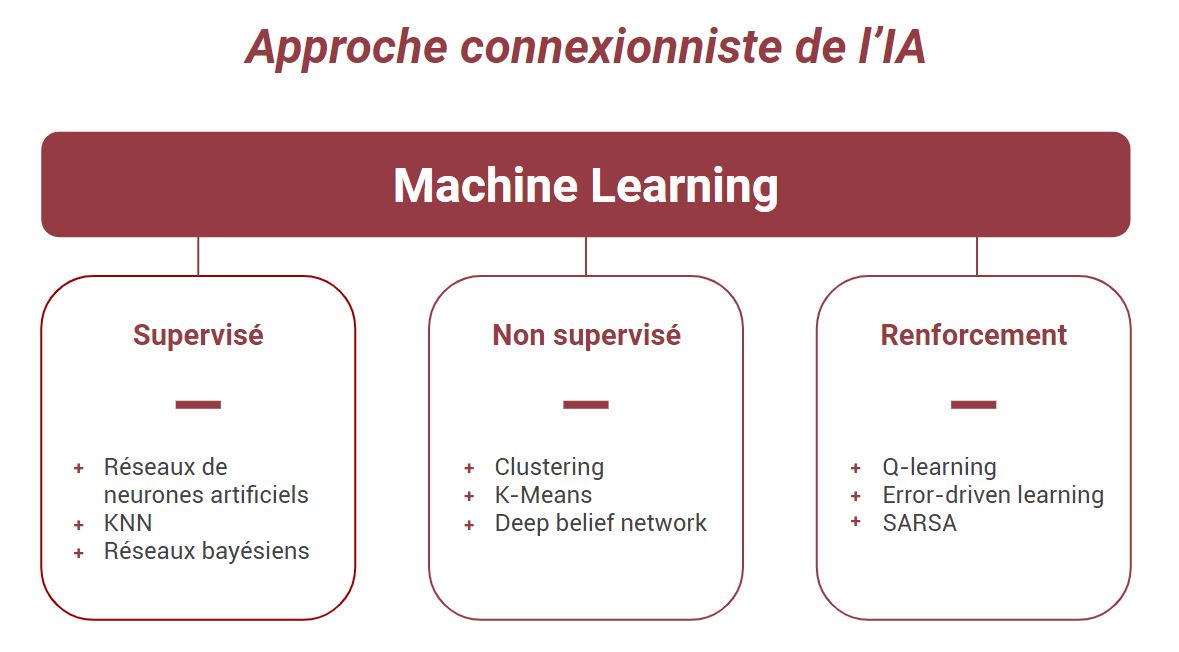
Trois grands sous-domaines du machine learning,
et quelques exemples d’algorithmes au sein de chacun.
Notons que le réseau de neurones artificiels est un parmi d’autres.
Cette révolution des algorithmes… qui n’en sont pas
Ces “Réseaux de Neurones Artificiels” ou “Artificial Neural Network” (que j’abrègerai ANN tout du long) ont un rapport à l’intelligence bien particulier. Par défaut, ils donnent des résultats aléatoires, car ils ne sont pas “entraînés”. L’entraînement va consister à présenter à cet ANN des exemples de cas à traiter. Sa capacité “d’entraînement” va dépendre de sa structure : le nombre et l’agencement des neurones artificiels. Si cette structure atteint une certaine complexité, on parlera alors de “Deep Learning”.
Un cas d’école ; pour qu’un ANN différencie la photo d’un chat de la photo d’un chien, on va lui donner des photos de chat et de chien, tout en précisant à chaque fois la bonne réponse. Durant cet entraînement, les valeurs contenues dans l’ANN vont être modifiées, ajustées, pour que les résultats correspondent à notre demande. Suite à cela, on va pouvoir présenter la photo d’un animal à l’ANN, sans lui donner la réponse, et il nous donnera son avis, basé sur son entraînement.
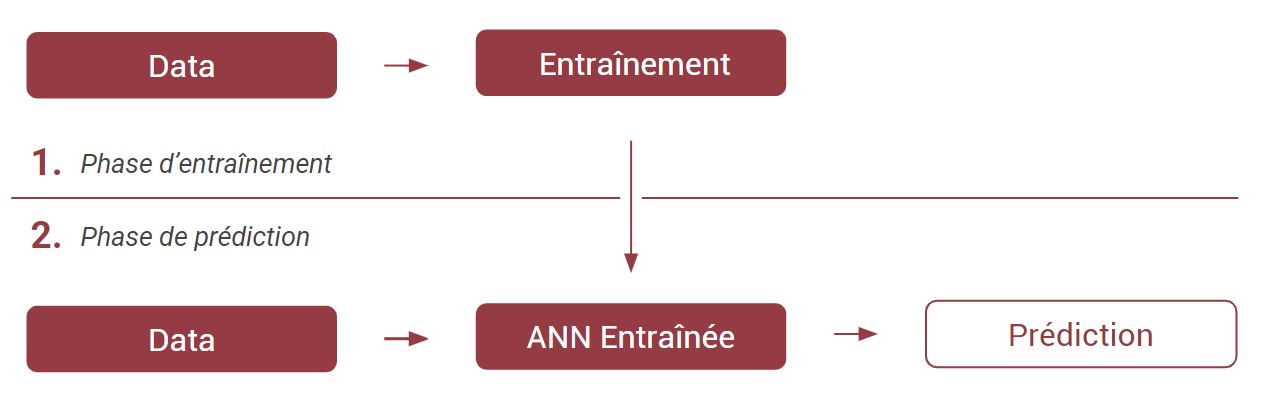
Aujourd’hui assez populaire, cette approche-là est pourtant incongrue par certains aspects. L’ANN a le même état de départ, qu’on lui fasse différencier des photos d’animaux ou des marques de voitures. Ce qui explique tout à la fois sa praticité d’usage pour les développeurs (une solution pour tous les problèmes !) et à la fois sa lourdeur. C’est-à-dire qu’à l’étape 0, il n’y a aucun “algorithme”. C’est l’entraînement qui va “générer l’algorithme”, et l’ANN n’est rien d’autre que le format de description de cet algorithme.

L’absence d’explications
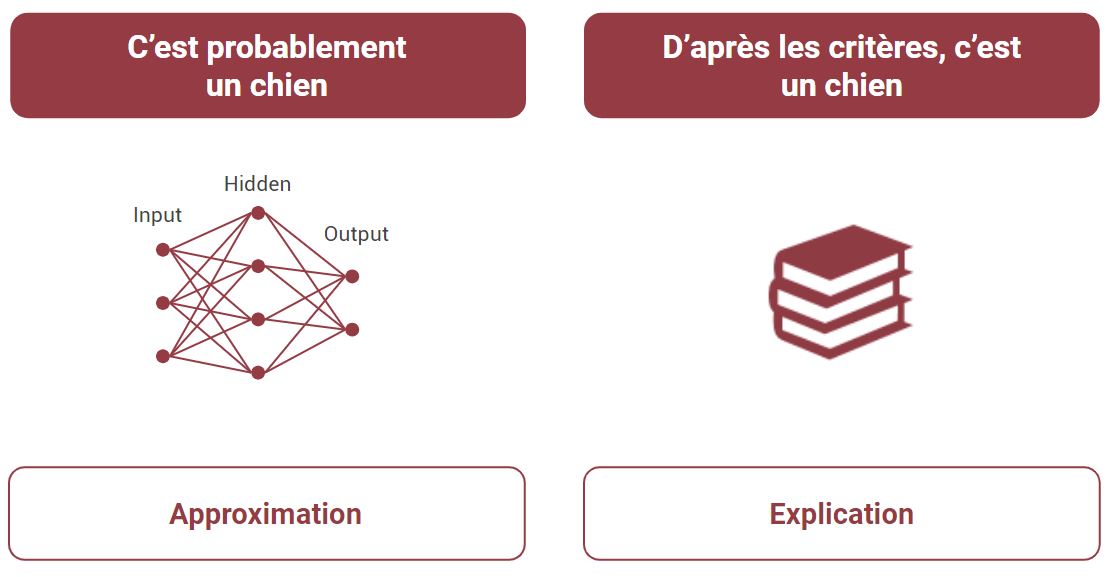
D’où le talon d’Achille des ANN ; pourquoi telle décision a-t-elle été prise ? Certains tentent une pseudo-explication en traçant l’activité des neurones pour savoir quelle partie de l’image a été principalement prise en compte pour la décision. Mais ça n’en reste pas moins un système non explicable par nature ; simplement parce que c’est un système quantitatif et statistique, là où l’explication doit être de nature qualitative. Une équation mathématique n’est pas une explication. Quel que soit le scénario, l’explication d’un ANN sera toujours “C’est la bonne réponse en moyenne”. Il n’y a aucune notion explicite de l’anatomie animale par exemple.
Que faire donc, quand le système prend une mauvaise décision ? On ajoute de la data !
C’est à la fois la force et la limite des ANN ; la data est tout ce qui existe. Nul besoin de spécialistes du monde animal, l’ANN ne comporte aucune expertise, et il n’en contiendra jamais. L’ANN est à l’opposé de la théorie ; il ne fait que mimer approximativement.
L’explicabilité de l’intelligence artificielle est pourtant un enjeu majeur pour le développement de l’IA dans les secteurs critiques, notamment pour les voitures autonomes, dont les accidents mortels amènent un besoin d’explication. Des acteurs comme la DARPA ou IBM investissent sérieusement sur ce sujet.
Ces “boîtes noires” posent également une problématique de performance. S’entraînant longuement pour des tâches ultra-spécifiques, c’est une vague d’algorithmes jetables qui se déploient dans les entreprises, c’est-à-dire, des solutions sur lesquelles on ne peut pas capitaliser de savoir-faire technologique, et qui sont souvent mises en échec dès lors que le contexte métier évolue, de par la quantité de ressources (humaines et temporelles) nécessaires eu ré-entraînement du système.
C’est la faute à la data
Par opposition aux algorithmes dits “symboliques” (une autre grande famille de l’IA), qui comportent une expertise, une modélisation, ou un raisonnement, les ANN ne peuvent pas être remis en cause en eux-mêmes, car… ils ne sont “rien”. Tout est dans la data.
On peut modifier le modèle lui-même (la structure de l’ANN), estimant qu’il n’est pas assez complexe par exemple, mais in fine, on retombera toujours sur la question des données.
Ainsi, lorsqu’après un entraînement, l’ANN confond un chiot avec un chat … on va ajouter de la donnée, éventuellement en focalisant sur le type de donnée qu’on estime manquant.
La photo est le cas typique d’usage des ANN, car il y a encore peu d’alternatives algorithmiques aux approches statistiques. C’est aussi un exemple très pédagogique de l’usage des ANN. Dans d’autres domaines en revanche, les solutions disponibles sont plus riches. Sur les différents défis d’analyse du langage humain par exemple, toute la linguistique va apporter un angle d’analyse du langage, modélisable dans une IA.
Alors, comment mettre en compétition un ANN et une IA linguistique ? C’est là que le trou noir argumentatif de l’ANN entre en place. Ce fameux aphorisme, une étrange pirouette face au vérificationnisme scientifique, qui met fin à toute conversation lorsque les résultats sont en défaut ; “Si ça ne marche pas, c’est juste qu’il faut plus de data”.

C’est la faute aux institutions
Cette aporie, que l’on résume parfois par “All models are wrong”, ne laisse aucune place pour un concurrent potentiel ; en effet l’algorithme est parfait “par destination”, c’est la data qui est en défaut. C’est aussi l’acte de renvoyer la balle aux institutions. C’est la faute à la GDPR, c’est la faute à l’entreprise qui n’a pas assez de data, etc. En somme, le Machine Learning dédouane l’expert d’un manque d’expertise.
Cette aporie de la data a bien sûr pour postulat l’idée que la data serait une ressource infinie. Ce n’est certainement pas une lecture économique de la question, ni même une lecture réaliste. Mais c’est intéressant de remarquer que techniquement, si la valeur d’un ANN se fait sur sa capacité à savoir généraliser, c’est-à-dire analyser correctement des situations éloignées de son entraînement, de l’autre côté, cette tendance d’aller vers un entraînement qui n’en finit jamais constitue en définitive une lente convergence vers l’accumulation en base de données… de tous les cas possibles. Ce qui est par ailleurs particulièrement ironique dans un moment où il y a une tendance de fond à penser que “la vraie IA c’est le Machine Learning”.
Le traitement du langage au coeur du sujet
On observe cela typiquement dans le NLU (Natural Language Understanding), quand on entraîne un système à reconnaître correctement des demandes (“intentions”). Un chatbot de commande de pizza par exemple.
Si l’on vise à un haut taux de fiabilité, l’entraînement va donc nécessiter un volume d’exemples de commande de pizza toujours plus grand, et on va avoir de plus en plus l’impression de fournir toutes les formulations possibles !
C’est aussi pour cela que les solutions qui traitent de l’anglais ne sont pas représentatives de la fiabilité générale du Machine Learning sur les langues, que soit sur la reconnaissance vocale ou sur le NLU. La variabilité de l’anglais est faible. Par opposition, l’espagnol par exemple, comporte beaucoup plus de flexions (modifications possibles d’un même mot : conjugaisons, pluriel, etc). Le besoin de donnée, en conséquence, est plus important. On trouvera donc un rapport fiabilité / quantité de données, moins intéressant.
La notion d’intelligence challengée
Le besoin d’énormes volumes de données est à l’opposé de l’intelligence : les bons algorithmes sont plutôt ceux qui savent sélectionner la bonne information pour prendre une décision. Par opposition, dans la lecture pure data de l’intelligence, c’est comme si pour apprendre à un enfant à lire, et sans qu’il ne sache rien de la lecture, on se contentait de le laisser seul avec des centaines de livres. Et, plus amusant encore, face à l’échec, on décidait d’en rajouter quelques centaines supplémentaires !
Même sur des sujets comme la reconnaissance vocale, qui a le point commun avec le traitement de l’image de ne pas vraiment avoir d’alternatives au Machine Learning pour fonctionner, on oublie que le Machine Learning n’est pas le seul algorithme impliqué. Et ainsi on oublie à quel point les choix de modélisation et représentation linguistique sont prépondérants pour que la reconnaissance vocale soit opérationnelle, et que le Machine Learning en est terriblement dépendant. C’est pour cela que beaucoup de fournisseurs de reconnaissance vocale ont assez peu de langues disponibles. Les langues agglutinantes par exemple (Finnois, Turc…), qui sont linguistiquement éloignées de l’anglais, sont peu représentées dans les offres.
Le Machine Learning comble un trou dans la raquette de l’IA. Mais la montée subite de la mode des réseaux de neurones artificiels a aussi changé complètement le rapport à l’IA : il est maintenant normal de se plaindre infiniment du manque de données, et étrange de se pencher sur la modélisation des problèmes et leur théorisation.
C’est une déviance qui n’est probablement pas sans rapport avec les intérêts des acteurs économiques à accumuler le maximum de données, ou avec le cloisonnement des disciplines. Cette déviance a pour effet secondaire d’occuper les data-scientists, une ressource précieuse et rare, à brasser longuement de la donnée pour alimenter les modèles, ce qui n’est bien sûr par leur valeur ajoutée.
Cette approche par la data a beaucoup de faiblesses qui ne sont pas suffisamment exprimées, faute de connaissance des alternatives, et de l’IA plus généralement. En particulier, le manque de réutilisabilité des algorithmes générés, ou encore la pénibilité d’évolution des solutions, en opposition avec l’agilité nécessaire à l’innovation.
La lumière est du côté de ceux qui iront en profondeur dans le discernement et l’analyse des options à disposition, ne tombant ni dans l’étroitesse d’esprit des modes, ni dans un mélange glouton et désordonné des approches possibles.
Thomas Solignac, CEO de Golem.ai



